

SAM 3: Segment Anything Model Explained
The Modern Era of Promptable Concept Segmentation with SAM 3.

The ability to find and segment anything in a visual scene is foundational for multimodal AI. This capability powers essential applications across diverse fields, including robotics, content creation, augmented reality, data annotation, and broader sciences.

Previous models in the SAM series (SAM 1 and SAM 2) introduced and focused on Promptable Visual Segmentation (PVS).
PVS defined the promptable segmentation task for both images and videos, typically relying on visual prompts such as points, boxes, or masks to segment a single object per prompt.
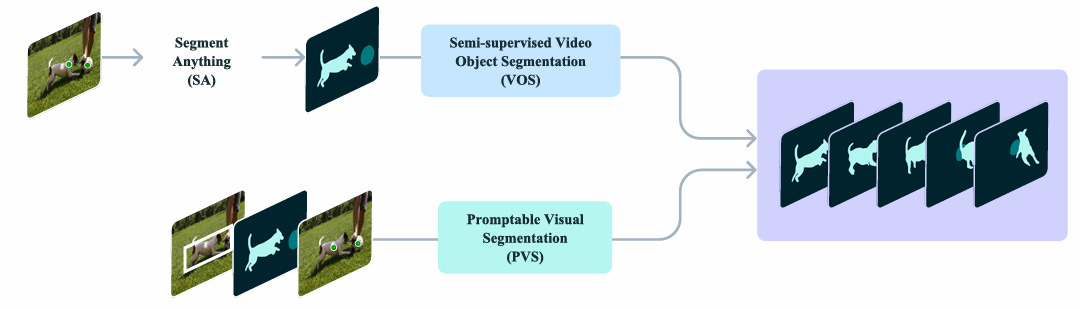
Although these methods are great for segmentation, they did not address the more general challenge of finding and segmenting all instances of a concept appearing anywhere in the input.
Meta presents Segment Anything Model (SAM) 3. To fill that gap. It is a unified model that achieves a step change in promptable segmentation in images and videos.

SAM 3 solves the generalized task known as Promptable Concept Segmentation (PCS). It’s defined by taking concept prompts, which can be short noun phrases (yellow school bus), image exemplars, or a combination of both, as input.
As output, PCS predicts segmentation masks and unique identities for every single object instance matching the concept, while also preserving object identities across video frames.
The model and the associated new benchmark, Segment Anything with Concepts (SA-Co), are open-sourced for promptable concept segmentation research.
In this article, we will cover:
Formalizing the Task: Promptable Concept Segmentation (PCS)
SAM 3 Model Architecture: A Unified Detector-Tracker
Advanced Capabilities and Limitations
Performance Evaluation and Benchmarks
Data Engine: Scaling Concepts with Human- and AI-in-the-Loop
If you want to fine-tune a SAM 3 model using a domain-specific dataset, check out our guide on computer vision datasets.
Illustrated guide video of the SAM 3:
Formalizing the Task: Promptable Concept Segmentation (PCS)
We must first understand the new task it solves to understand SAM 3. The authors define Promptable Concept Segmentation (PCS) as a process that takes specific prompts as input and returns segmentation masks and unique identities for all matching object instances.
Defining Concept Prompts
Unlike PVS, which uses spatial cues (clicks), PCS is driven by semantic concepts. SAM 3 accepts three specific types of inputs to define a concept:
Noun Phrases (NPs): The model accepts simple text descriptions. These are constrained to short noun phrases, such as a yellow school bus or a penguin. And it ensures the model focuses on recognizing atomic visual concepts rather than complex reasoning.
Image Exemplars: Users can provide a bounding box around an object to serve as an example. This tells the model, “find everything that looks like this”.
Combined Prompts: Then, both text and visual exemplars were combined to refine the search target.
Operational Flow and Interactivity
The PCS task is fully interactive, and a user might input the text prompt “fish.” The model attempts to segment every fish in the image or video. If the model misses a specific instance (a false negative) or segments a rock instead of a fish (a false positive), the user can intervene.
Users resolve these errors by adding refinement prompts. These can be positive bounding boxes (to add missing objects) or negative bounding boxes (to remove incorrect ones).
Crucially, in video contexts, the model must track these objects and preserve their unique identities across frames.

The Challenge of Ambiguity
A major challenge in open-vocabulary segmentation is ambiguity. A simple phrase like mouse could refer to a computer peripheral or a rodent. Subjective descriptors like large or cozy are even harder to ground visually.
Furthermore, boundaries are often ambiguous; for example, does a mirror mask include the frame or just the reflective glass?.
SAM 3 addresses them through two main avenues:
Data Pipeline Design: The training data is curated to minimize ambiguity where possible.
Ambiguity Head: The model architecture includes a specialized module that handles scenarios with multiple valid interpretations.
SAM 3 Model Architecture: A Unified Detector-Tracker
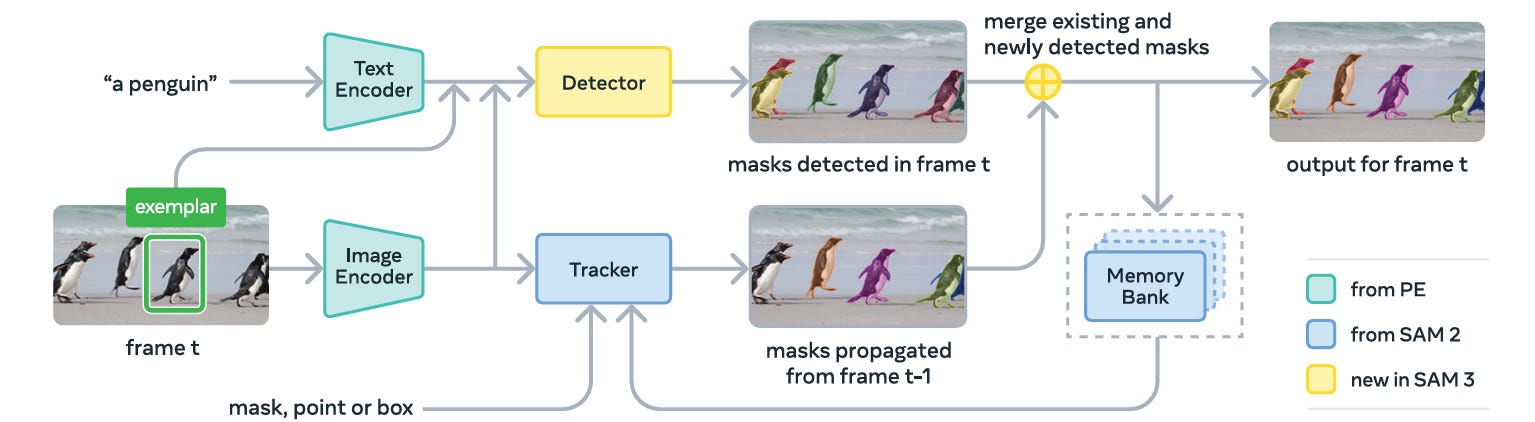
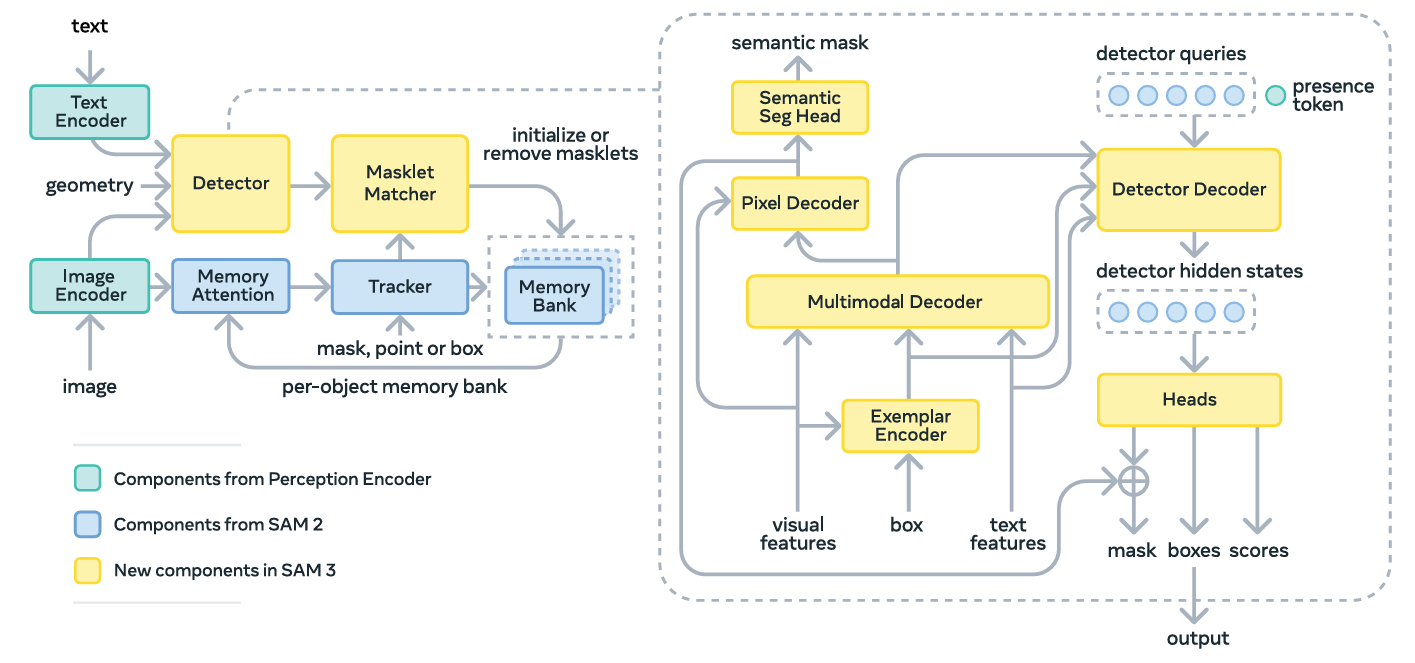
SAM 3 is built as a unified system that supports both the new PCS task and the traditional PVS task. The architecture consists of an image-level detector and a memory-based video tracker.
The Shared Backbone: Perception Encoder
The root of SAM 3 is the Perception Encoder (PE) backbone. Both the detector and tracker share this vision encoder to ensure that the heavy lifting of processing visual features is done once per image or frame.
The PE is pretrained on aligned vision-language data and lets the model start with a strong understanding of how text relates to visual concepts.
This shared backbone processes the input image and outputs unconditioned embeddings that are fed into the detector and tracker modules.
The Detector: Image-Level Intelligence
The detector in SAM 3 finds objects within a single image, and it follows the general DETR (Detection Transformer) paradigm.
Input Fusion
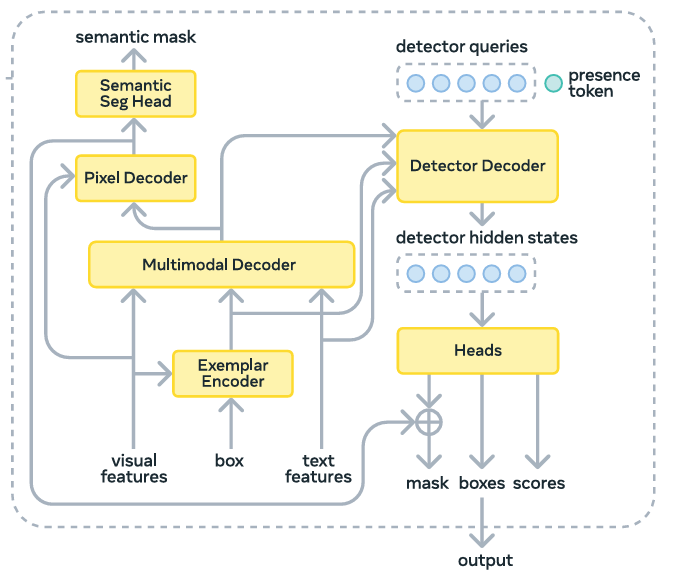
The detector receives two streams of information, the image embeddings from the backbone and the prompt tokens.
Prompt tokens are a combination of text tokens (from the noun phrase) and image exemplar tokens (if boxes are provided).
A fusion encoder conditions the image embeddings by cross-attending to these prompt tokens. This process effectively “tells” the image features what to look for.
Decoupled Recognition
The Presence Head is the most significant architectural innovation in SAM 3. In typical detection models, each object query attempts to identify what an object is and its location at the same time.
This can be counterproductive because recognition needs global context, while localization needs a local focus.
SAM 3 decouples these tasks. It introduces a learned global presence token.
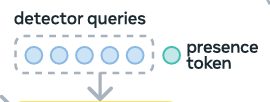
The presence token’s sole job is to predict whether the target concept exists anywhere in the image. It calculates the probability:
p(NP is present in input)
Meanwhile, the individual object queries focus solely on the localization problem:
p(query matches | NP is present in input)
The final score for any detected object is the product of its own localization score and the global presence score. And decoupling improves detection accuracy when the model encounters hard negatives.
The Decoder and Segmentation Head
The detector uses a DETR-like decoder where learned object queries cross-attend to the conditioned image embeddings.
The output is passed to a mask head adapted from MaskFormer to produce the final segmentation masks.
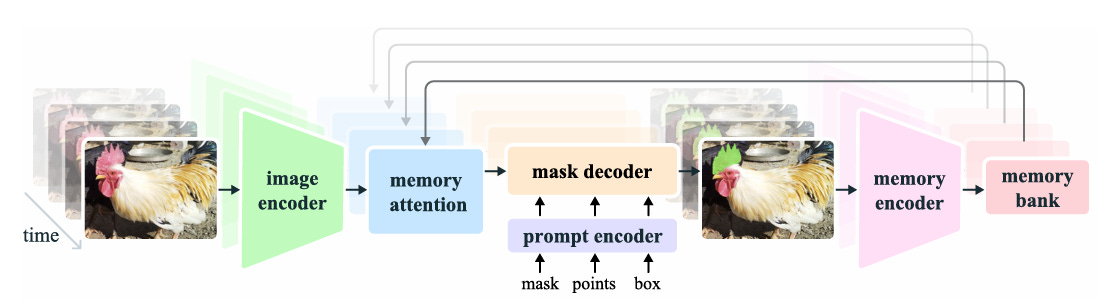
The Tracker: Video Capabilities
For video inputs, SAM 3 inherits the transformer encoder-decoder architecture from SAM 2.
Propagation Mechanism
The tracker’s primary objective is to separate identities across the video. On the first frame, the detector identifies all objects matching the prompt. A masklet (spatio-temporal mask) is initialized for every detected object.
In later frames, the tracker forecasts the new position of these masklets based on their previous movements.
It uses a memory bank to store features from past frames and conditioning frames (frames where the object was first detected or prompted).
Matching and Updating
At every time step, the model performs two actions:
Detect: The detector finds new objects in the current frame (Ot).
Propagate: The tracker predicts where existing objects have moved (M^t).
A matching function compares the propagated masklets with the newly detected objects.
If they overlap significantly, the masklet is updated. If a new detection does not match any existing masklet, a new masklet is created.
Temporal Disambiguation Strategies
SAM 3 uses some specific strategies to maintain data hygiene since tracking is prone to errors, such as drifting or creating duplicate tracks for the same object.
Track Confirmation Delay: The model delays showing output for a short window. During this time, it verifies if a candidate masklet is consistently matched to detections. If not, it is discarded as a spurious detection.
Periodic Re-Prompting: To handle occlusions or drift, the tracker is periodically re-initialized using high-confidence detection masks from the current frame. This ensures the memory bank contains recent, reliable visual references.
Data Engine: Scaling Concepts with Human- and AI-in-the-Loop
A model is only as good as its training data, and to achieve the generalization required for PCS, existing datasets were insufficient. They lacked the necessary diversity of concepts and the volume of hard negatives required to train a model.
To solve this, the researchers built a scalable Data Engine that leverages both human annotators and AI models to produce high-quality data at scale.
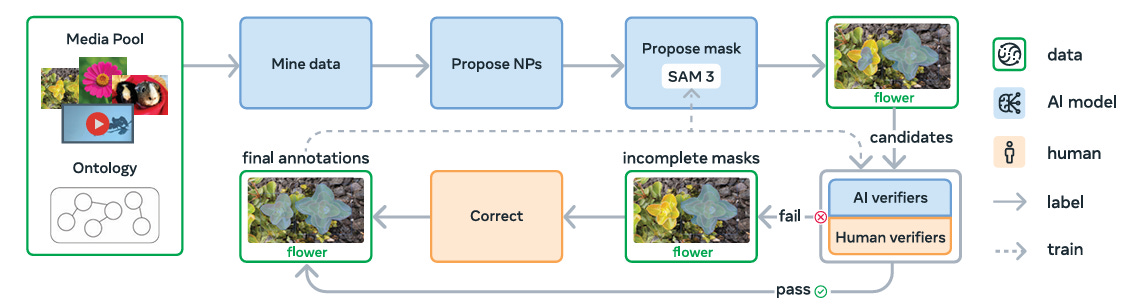
Three Key Innovations in Data Curation
The data engine improves upon prior approaches in three specific ways:
Media Curation
Most large datasets rely on homogenous web-scraped images. SAM 3’s engine curated diverse media domains to ensure the model was exposed to varied visual contexts beyond standard internet photos.
Label Curation via Ontology
The team built the SA-Co Ontology, a massive graph containing 22.4 million nodes based on Wikidata. This allowed them to mine specific, long-tail concepts.
Furthermore, they utilized multimodal Large Language Models (MLLMs) as AI annotators to generate noun phrases and, crucially, hard negatives.
Hard negatives are phrases describing objects that are not in the image but are semantically similar to objects that are (labeling a dog as a negative when the image contains a cat).
Label Verification with AI Verifiers
Verification is often the bottleneck in data annotation. To accelerate this, the team fine-tuned Llama 3.2 models to act as AI Verifiers. These models performed two tasks:
Mask Verification (MV): Checking if a generated mask accurately covers the object described by the prompt.
Exhaustivity Verification (EV): Checking if all instances of the concept in the image have been masked.
These AI verifiers achieved near-human accuracy and doubled the throughput of the annotation pipeline.
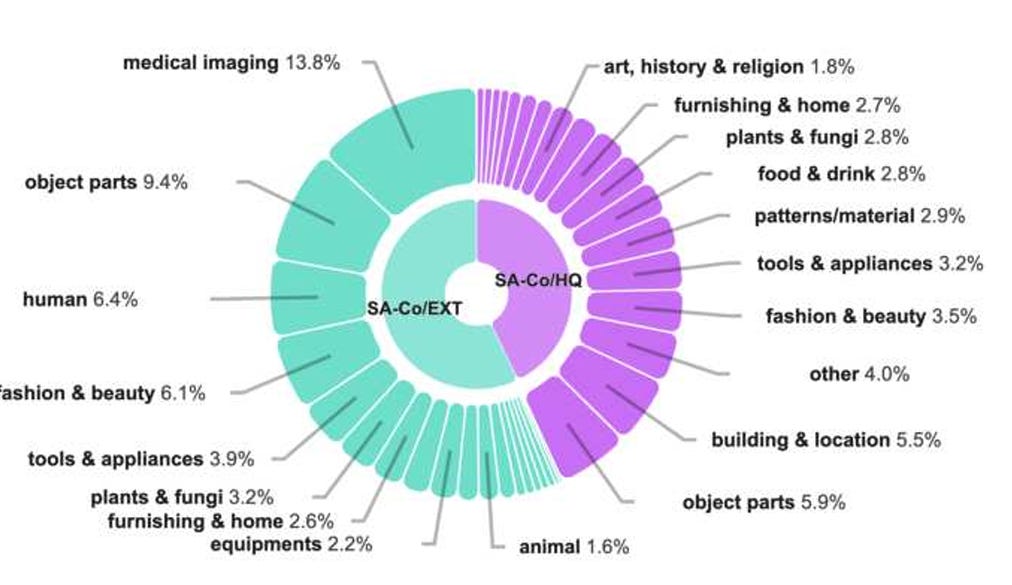
Dataset Results
The dataset engine produced three distinct datasets for training:
SA-Co/HQ: A high-quality image dataset with 5.2 million images and 4 million unique noun phrases.
SA-Co/SYN: A synthetic dataset containing 39.4 million images and over 1 billion masks.
SA-Co/VIDEO: A video dataset with 52.5K videos and 467K masklets.
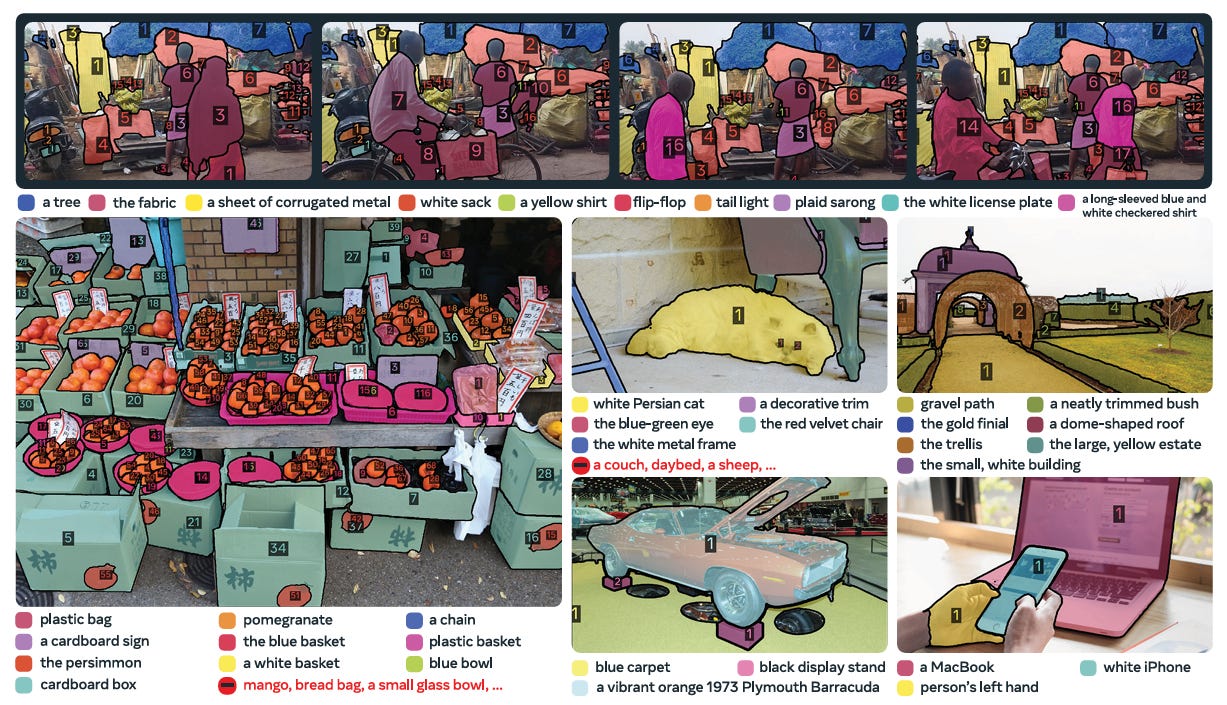
Performance Evaluation and Benchmarks
The researchers introduced a new benchmark and a new metric to measure success in PCS.
The SA-Co Benchmark
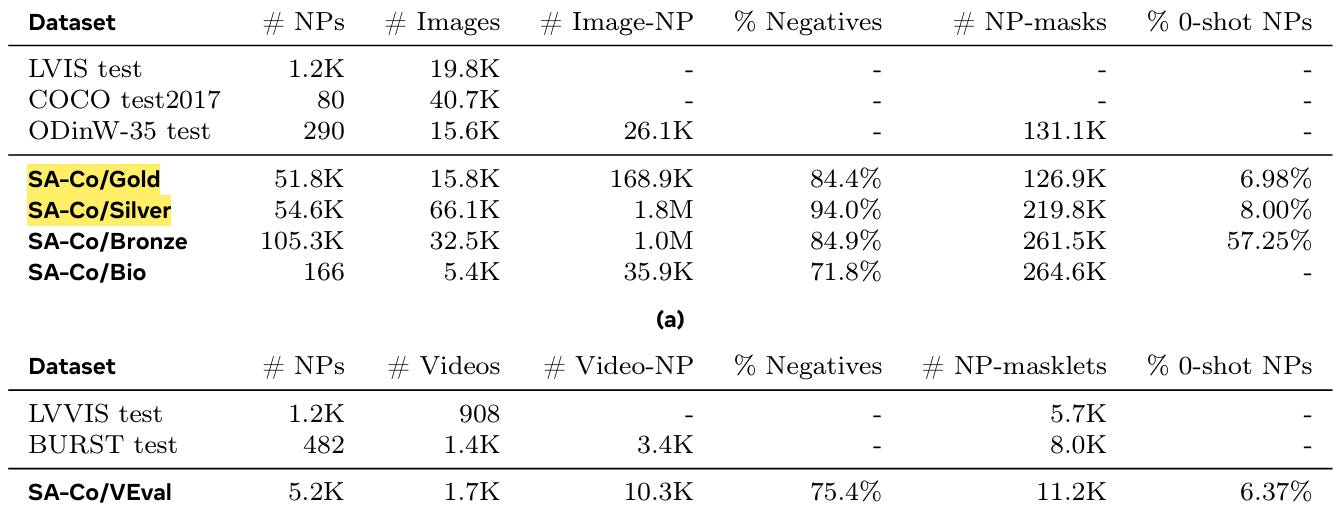
The Segment Anything with Concepts (SA-Co) benchmark is a massive evaluation set containing 207,000 unique concepts across 120,000 images and 1,700 videos.
It contains over 50 times more concepts than existing benchmarks like LVIS, providing a rigorous test of open-vocabulary capabilities.
The benchmark is split into varying difficulties:
SA-Co/Gold: Contains annotations from three separate experts to account for ambiguity.
SA-Co/Silver: Contains single human annotations.
Metrics for PCS
Standard metrics like Average Precision (AP) are ill-suited for open-vocabulary tasks because they do not account for calibration, which is how confident the model is in its prediction.
SAM 3 uses a composite metric called classification-gated F1 (cgF1). This metric is the product of two sub-scores:
Localization (pmF1): How accurately the model segments the object pixels.

Image-Level Classification (IL_MCC): How accurately the model determines if the concept is present in the image at all.

The combination of these two metrics is cgF1 (classification-gated F1):
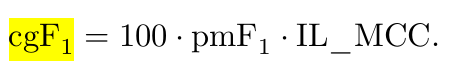
Image PCS Results
In zero-shot evaluations, SAM 3 sets a new state-of-the-art.
On the SA-Co/Gold benchmark, SAM 3 achieves a score that is more than double that of the strongest baseline, OWLv2.
On the established LVIS dataset, SAM 3 reaches a zero-shot mask AP of 48.8, significantly surpassing the previous best of 38.5.
Video PCS Results
For video segmentation, SAM 3 was evaluated against baselines like GLEE and combinations of LLMDet with trackers.
SAM 3 outperformed these baselines across the SA-Co/VEval subsets (SA-V, YT-Temporal-1B, SmartGlasses).
On the SA-Co/VEval benchmark, it achieved over 80% of human performance metrics (measured in pHOTA).
Visual Segmentation (PVS) Improvements
Crucially, SAM 3 did not sacrifice its core visual segmentation ability to gain concept understanding. It improved upon SAM 2 in visual prompting tasks.
In Video Object Segmentation (VOS), SAM 3 outperformed prior work by 6.5 points on the challenging MOSEv2 dataset.
It also achieved higher average intersection-over-union (mIoU) scores on interactive image segmentation compared to SAM 2.
Advanced Capabilities and Limitations
Beyond standard segmentation, SAM 3 enables new agentic workflows and demonstrates impressive efficiency.
SAM 3 Agent: Handling Complex Language
While SAM 3 is trained on simple noun phrases, it can be combined with Multimodal Large Language Models (MLLMs) to handle complex queries. This system is called SAM 3 Agent.
In this setup, the MLLM acts as a planner. If a user asks a reasoning-heavy question (segment the object that is used to cut food), the MLLM reasons that the object is a knife. It then prompts SAM 3 with the noun phrase “knife” to generate the mask.
Agentic approach lets SAM 3 to surpass previous zero-shot models on reasoning segmentation benchmarks like ReasonSeg and OmniLabel without any specific training on those tasks.

Limitations
Despite its advances, the authors are transparent about SAM 3’s limitations:
Generalization to Niche Domains: The model struggles with zero-shot generalization for very fine-grained concepts that are outside its training data, such as specific aircraft types or specialized medical terms. But, fine-tuning or using domain-specific synthetic data can mitigate this.
Simple Noun Phrases Constraint: The core model accepts only simple noun phrases. It cannot process long referring expressions or queries requiring logic without being paired with an MLLM.
Video Inference Cost: Because SAM 3 tracks every object with a masklet, the computational cost scales linearly with the number of tracked objects. This makes real-time inference challenging for videos with many concurrent objects.
Conclusion
SAM 3 bridges the gap between understanding what is in an image and pinpointing exactly where it is. The success of SAM 3 is as much about the model architecture as it is about the data. The creation of the massive, diverse SA-Co datasets through a human-AI collaborative engine sets a new standard for how vision models should be trained.
Demo: https://www.segment-anything.com
Website: https://ai.meta.com/sam3